Automating Inference using S3 Lambda Triggers and Inference Jobs
This tutorial is designed to demonstrate how you can provision trainML resources programmatically based on events occurring in other environments. It uses AWS S3's Event Notifications with Lambda. Other cloud providers have similar capabilities.
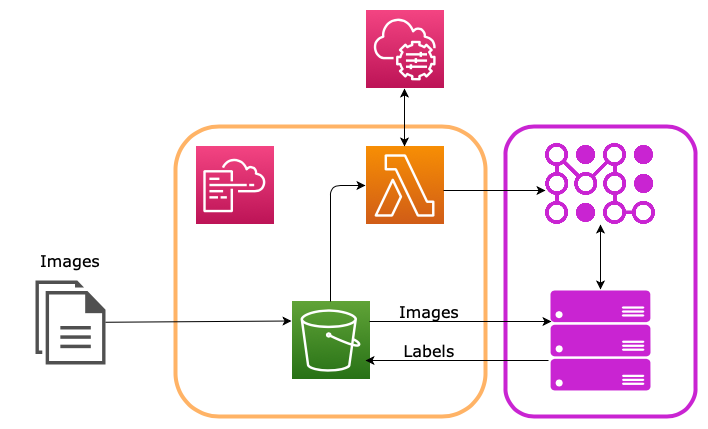
In the tutorial, we will use CloudFormation to create an S3 bucket that will invoke a Lambda function when new images are loaded into the /incoming folder. This Lambda function will create a trainML Inference Job to evaluate the images with a pretrained model and save the predicted image classes back to the /processed folder in the same S3 bucket.
The code for this tutorial is located here: https:
Executing the tutorial once should cost less than $0.01 in trainML cost. All AWS resources should be included in the AWS Free Tier, but additional costs may apply.
Prerequisites
Before beginning this tutorial, ensure that you have satisfied the following prerequisites.
- A valid trainML account with a non-zero credit balance
- The local connection capability prerequisites
- A valid AWS account with the AWS CLI installed and configured with the correct permissions
- AWS Keys configured for your trainML account
- A terminal that can run bash scripts
AWS Setup
The majority of the AWS setup is performed by the provide CloudFormation templates. The only remaining manual steps are to place the trainML API keys in a secure location accessible to Lambda and set the IAM policy for the trainML IAM user.
Manual Configuration
API Key Setup
Programmatic access to trainML resources is provided through the trainML SDK. To allow a Lambda function to use the SDK, it must have access to a trainML API key for your account. The code in this tutorial expects they keys to be stored as two SecureString parameters in AWS Parameter Store.
Once you have generated a credentials.json file from the trainML account settings page, create two new AWS Parameter Store parameters named /trainml/api_user and /trainml/api_key. Set their values to the user and key from the credentials.json file, respectively. Both parameters must be the SecureString type, and the tutorial assumes you are using the default AWS KMS key for encryption. If you use a different KMS key, you will need to modify the Lambda execution policy in the CloudFormation template to give Lamdba access to decrypt the parameter.
IAM User Policy
In order to access the new S3 data and place the results back, you must configure AWS Keys in the trainML platform. The IAM user you use for this must have a policy that grants the correct access to allow access to the resources required. Attach the following policy to the IAM user you created for trainML.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": ["s3:GetObject", "s3:ListBucket"],
"Resource": [
"arn:aws:s3:::example-bucket-*",
"arn:aws:s3:::example-bucket-*/*"
]
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "s3:PutObject",
"Resource": ["arn:aws:s3:::example-bucket-*/*"]
}
]
}
This policy will grant read/write access to any S3 bucket in your account with a name starting with example-bucket-*. The bucket names in the provided template are actually dynamically generated by CloudFormation, since these names must be globally unique.
Creating the Stack
The rest of the AWS resources will be automatically created through CloudFormation. Pull the trainML examples
repository and navigate to the /inference/s3_triggered folder. To create the stack, run the following command:
./create_stack.sh
The contents of the script are beyond the scope of the tutorial. It's effect will be to create an S3 bucket to deploy the Lambda code, package and upload the Lambda code to the deployment bucket, create the S3 bucket for receiving the new input data, create the Lambda function itself with its execution role, and setup the Lambda event trigger on the S3 bucket while avoiding circular dependencies.
Once the script finishes, everything will be setup to process new data.
Classifying New Images
The images.zip file in the repository contains 5 images from the ImageNet validation set to simulate new images generated as part of your business's operations. To upload these to the /incoming folder in the S3 bucket, running the following:
./push-new-images.sh
This will cause the lambda function code to run, which will extract the uri of the new data from the event data and create a new trainML inference job using that data as the input.
Since this example is providing a zip file as the input_uri, the file will be automatically extracted prior to the job starting, so all the images should be located in the root of the TRAINML_DATA_PATH location (see environment variables). The inference code then iterates through each .JPEG file it finds in the TRAINML_DATA_PATH and uses a pre-trained vgg16 model to predict the top 5 classes for each image. It saves the predictions to .json files with the same names as the images in the TRAINML_OUTPUT_PATH. When the job finishes, all files in the TRAINML_OUTPUT_PATH are zipped into a file with the job name and uploaded to the /processed folder in the same S3 bucket (as specified by the output_uri in the job creation dict).
You can view the status of the job on the Inference Job Dashboard as well as view the job logs. The job will automatically stop when inference is complete and the output data is uploaded. Navigate to the S3 console in your AWS account and open the bucket with the name trainml-example-inference-s3-trigger-databucket-<random string>. In the /processed directory, you will see a zip file. Download this and extract it to review the model predictions.
Cleaning Up
To remove the AWS resources created by the create-stack.sh script, run:
./delete-stack.sh